 Image credit: Unsplash
Image credit: Unsplash
Abstract
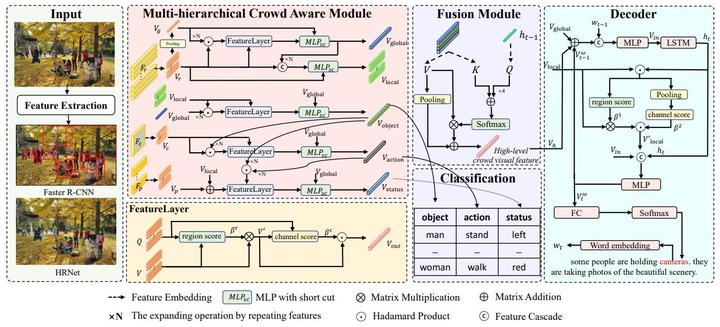
Making machines endowed with eyes and brains to effectively understand and analyze crowd scenes is of paramount importance for building a smart city to serve people. This is of far-reaching significance for the guidance of dense crowds and accident prevention, such as crowding and stampedes. As a typical multimodal scene understanding task, image captioning has always attracted widespread attention. However, crowd scene understanding captioning is rarely studied due to the unobtain-ability of related datasets. Therefore, it is difficult to know what happens in crowd scenes. In order to fill this research gap, we propose a crowd scenes caption dataset named CrowdCaption which has the advantages of crowd-topic scenes, comprehensive and complex caption descriptions, typical relationships and detailed grounding annotations. The complexity and diversity of the descriptions and the specificity of the crowd scenes make this dataset extremely challenging to most current methods. Thus, we propose a Multi-hierarchical Attribute Guided Crowd Caption Network (MAGC) based on crowd objects, actions, and status(such as position, dress, posture, etc.) aiming to generate crowd-specific detailed descriptions. We conduct extensive experiments on our CrowdCaption dataset, and our proposed method reaches the state-of-the-art (SoTA) performance. We hope the CrowdCaption dataset can assist future studies related to crowd scenes in the multimodal domain. Our dataset and the code of the benchmark method will be released soon.